A Voice from the Crypt
March 16, 2020
After a
deluge of
anthropomorphic animals in
videos,
children are surprised at an older age that real
animals are not as
articulate as
Peppa Pig.
Darwin ascribed the animals' lack of
speech to inferior
brain development, but later
scientific reasoning was that
nonhuman primates, such as
chimpanzees, can't talk since they didn't have as developed a
vocal tract as
humans.
However,
scientists at
Princeton University (Princeton, New Jersey) and the
Vrije Universiteit (Brussel, Belgium) analyzed
xray videos of a
long-tailed macaque in 2016 to build a
computer model of its vocal tract.[1-2] They found that this primate and its close primate
cousins could produce
intelligible speech. The reason that they don't is that there isn't sufficient
neural control of their vocal tract
muscles.[1-2]

Parrots can mimic human speech, and this allows Polly to get her cracker reward. A "talking" animal offers some entertainment, but it also needs to be fed; and, in the case of a parrot, the occasional fresh newspaper at the bottom of its cage. A talking machine is much more impressive, and such mechanical speech synthesis was accomplished by the German-Danish scientist, Christian Gottlieb Kratzenstein, who created a device based on the human vocal tract in 1779.
Charles Wheatstone (1802-1875) of the eponymous Wheatstone bridge produced a bellows-operated "speaking machine" in 1837 that included the vocal tract, and also a tongue and lips. A less complicated speech mechanism was contained in the 1824 "mama doll" of German inventor, Johann Nepomuk Maelzel (1772-1838).[3] Maelzel's mama doll's voice box was bellows-activated,[3-4] and US inventor, William A. Harwood, patented a variation of this device in which a child would blow air through a tube.[5]
(Modified Wikimedia Commons photograph of a Blue-fronted Parrot (Amazona aestiva) by Mateus Hidalgo,)
Such speaking devices use what's called
articulatory synthesis in which the
mechanism of human speech is physically
emulated. In our
computer age, the first step beyond the static mama doll
voice box was using a
computer to control a dynamic vocal tract, which was done in the 1960s. The next step was to
model the human speech mechanism, which includes the
resonant vocal chords,
acoustic wave propagation along the vocal tract, and sound modification by the lips and tongue, and
simulate it using
electronics.
Software has advanced to the point at which a
free and open source implementation is available in the form of
gnuspeech.
As I wrote in an
earlier article (Computers as Listeners and Speakers, November 4, 2013), human speech
information is contained in the
audio frequency band below 20 kHz, but intelligible speech, such as that found in early
telephone systems, is contained in
frequencies between
300-3400 Hz, with most of the
amplitude contained between 80-260
Hz. Telephone
research resulted in the first form of
digital encoding of speech in a system called the
vocoder, patented in 1939 by
Bell Labs acoustical engineer,
Homer Dudley.[6]
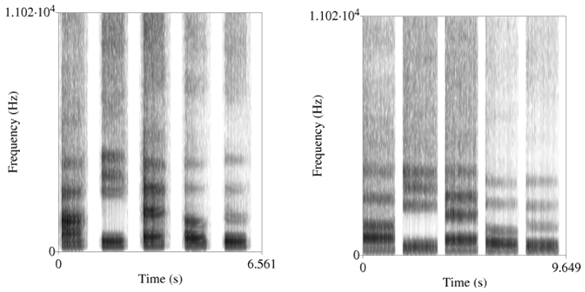
Spectrograms of the average female (left) and male (right) voicing of vowels. These are the English vowel sounds, 'eh' (bet), 'ee' (see), 'ah' (father), 'oh' (note), and 'oo' as in (boot). Note the overall lower frequencies of the male voice, as well as the slower male cadence. (Fig. 1 of ref. 7, licensed under a Creative Commons License. Click for larger image.)[7]
Dudley's
idea, as shown in the figure from his
patent,[6] was to
detect the
amplitude of the speech
signal in
audio bands selected by a bank of
audio filters. Instead of the speech signal itself, these amplitudes could be
transmitted to a remote bank of
oscillators to reconstructed the signal. All this was a
tour de force in 1939 when
vacuum tubes were used to perform the necessary
bandpass filtering and amplitude detection.
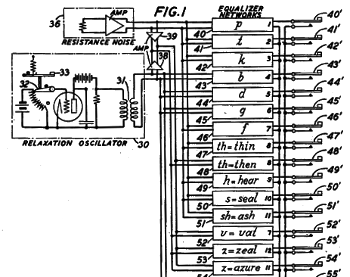
Portion of fig. 1 of US Patent No. 2,194,298, "System for the artificial production of vocal or other sounds," by Homer W. Dudley, March 19, 1940.[6]
As the circuit shows, Dudley realized that white noise is an important component of speech.
(Via Google Patents.[6] Click for larger image.)
Dudley's research was extended to the development of
speech synthesis using the combined techniques of
formant synthesis and
linear predictive coding (LPC).[8] These techniques were
commercialized in 1978 in the
Texas Instruments Speak & Spell toy. Several
decades later, my
e-book reader has an excellent
text-to-speech feature with both male and female speakers. My
Linux desktop computer has a simple text-to-speech program called
espeak. You can hear an
mp3 example of a portion of
Hamlet's To be, or not to be soliloquy rendered using espeak,
here.[9]
An
interdisciplinary research team from the
University of London (United Kingdom), the
University of York (York, United Kingdom), the
Leeds Museums and Galleries (Leeds, United Kingdom), the
Leeds General Infirmary (Leeds, United Kingdom), and the
University of Tübingen (Tübingen, Germany) have recently reported on an unusual project in voice synthesis in an
open access paper in the
journal,
Scientific Reports.[10-11] They used
computer tomographic (CT) scans of the vocal tract of a 3,000 year old
mummy to develop a precise model of its vocal tract and create a
3-D printed version of this vocal tract.[10] This simulated vocal tract was then used to create a vowel sound that's similar to that produced by modern humans.[10-11]
The mummy, sited at the
Leeds City Museum in
northern England, was that of an
Egyptian priest,
Nesyamun.[10-11] Nesyamun was a
scribe and a
high-ranking priest at the
Karnak temple in
Thebes who held his position during the
reign of
Ramses XI,
pharaoh of Egypt from 1099 BC-1069 BC.[11] The nature of the
specimen limited the scope of the study. The vocal tract has just a single
shape, this shape being the consequence of Nesyamun's
supine burial position.[11] The sound produced is just a
groan that sounds like
eeuuughhh, and it would be the sound made if his vocal tract came to life again in his
coffin.[11]
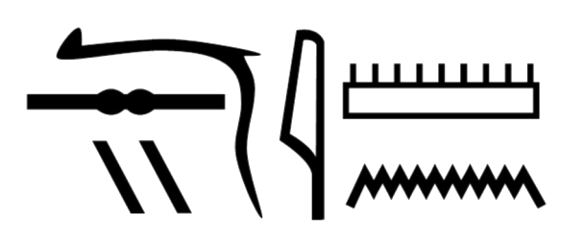
Nesyamun's name, spelled in Egyptian hieroglyphs, as inscription on his coffin. Nesyamun was a common name that translates to mean, "The one belonging to the God, Amun."[11] (Fig. 2 of ref, 10, licensed under a Creative Commons Attribution 4.0 International License.)
Nesyamun was a fitting object for this study, since he performed
rituals in
song and speech. He seemingly
died from an
allergic reaction in his mid-50s, and he
suffered also from
gum disease and heavily
worn teeth. The inscriptions on his coffin attest to Nesyamun's hope that his
soul would one day speak to the
gods as he had in his lifetime.[11] In a way, this scientific study fulfilled this
wish. Other obstacles to generation a true sound is that the tongue is missing, and there's a lack of the
fleshy,
vibrating, vocal folds that add
timbre to a voice.[11] In any event, this
recorded sound will add an interesting dimension to the museum display.[11]
References:
- W. Tecumseh Fitch, Bart de Boer, Neil Mathur, and Asif A. Ghazanfar, "Monkey vocal tracts are speech-ready," Science Advances, vol. 2, no. 12 (December 9, 2016), Article no. e1600723, DOI: 10.1126/sciadv.1600723.
- Michael Price, "Why monkeys can't talk—and what they would sound like if they could," Science, December 9, 2016.
- Patrick Feaster, "A Cultural History of the Edison Talking Doll Record," Thomas Edison National Historical Park Website.
- Daniel Tiffany, "Toy Medium: Materialism and Modern Lyric," University of California Press, March 8, 2000, p. 58 (via Google Books).
- William A. Harwood, "Improvement in Talking and Crying Dolls," U. S. Patent no. 189,935 (April 24, 1877).
- Homer W Dudley, "Signal transmission," US Patent no. 2,151,091, March 21, 1939.
- Daniel E. Re, Jillian J. M. O'Connor, Patrick J. Bennett and David R. Feinberg, "Preferences for Very Low and Very High Voice Pitch in Humans," PLoS ONE, vol. 7, no. 3 (March 5, 2012), Article No. e32719.
- Physical Audio Signal Processing, Voice Synthesis, Vocal Tract Analog Models, Free Books.
- The Linux command line is espeak "To be, or not to be--that is the question: Whether 'tis nobler in the mind to suffer the slings and arrows of outrageous fortune; or, to take arms against a sea of troubles, and by opposing end them."
- D. M. Howard, J. Schofield, J. Fletcher, K. Baxter, G. R. Iball, and S. A. Buckley, "Synthesis of a Vocal Sound from the 3,000 year old Mummy, Nesyamun True of Voice, Scientific Reports, vol. 10, Article no. 45000 (January 23, 2020), https://doi.org/10.1038/s41598-019-56316-y. This is an open access article with a PDF file here.
- Meilan Solly, "Listen to the Recreated Voice of a 3,000-Year-Old Egyptian Mummy," Smithsonian Magazine, January 24, 2020.
Linked Keywords: Deluge; anthropomorphic animal; video; child; children; animal; articulatory phonetics; articulate; Peppa Pig; Charles Darwin; speech; development of the nervous system; brain development; science; scientific; nonhuman primate; chimpanzee; vocal tract; human; scientist; Princeton University (Princeton, New Jersey); Vrije Universiteit (Brussel, Belgium); xray; crab-eating macaque; long-tailed macaque; computer model; cousin; intelligibility (communication); intelligible; neuron; neural; control; muscle; parrot; mimicry; mimic; Polly wants a cracker; entertainment; food; fed; >newspaper; cage; machine; mechanical; speech synthesis; Germany; German; Denmark; Danish; Christian Gottlieb Kratzenstein; Charles Wheatstone (1802-1875; eponym; eponymous; Wheatstone bridge; bellows; tongue; lips; mama doll; invention; inventor; Johann Nepomuk Maelzel (1772-1838); patent; patented; pneumatics; blow air through a tube; Wikimedia Commons; blue-fronted Parrot (Amazona aestiva); Mateus Hidalgo; articulatory synthesis; mechanism (biology); imitation; emulate; information Age; computer age; larynx; voice box; computer; mathematical model; resonance; resonant; vocal chord; acoustic wave; wave propagation; simulation; simulate; electronics; computer software; rFree and open source software; gnuspeech; information; audio frequency band; telephony; telephone system; frequency; frequencies; voice frequency; 300-3400 Hz; amplitude; hertz; Hz; research; digital data; digital encoding; vocoder; Bell Labs; acoustical engineering; acoustical engineer; Homer Dudley; spectrograms of vowel sounds; female; male; human voice; voicing; vowel; English language; cadence; Creative Commons License; idea; detector (radio); detect; amplitude; signal (electrical engineering); audio filter; transmission (telecommunications); electronic oscillator; tour de force; vacuum tube; band-pass filter; bandpass filtering; electronic circuit; white noise; Google Patents; speech synthesis; formant synthesis; linear predictive coding; commercialization; commercialize; Texas Instruments; Speak & Spell toy; decade; e-book reader; text-to-speech; Linux; desktop computer; espeak; mp3; Prince Hamlet; To be, or not to be; soliloquy; interdisciplinarity; interdisciplinary; University of London (United Kingdom); University of York (York, United Kingdom); Leeds Museums and Galleries (Leeds, United Kingdom); Leeds General Infirmary (Leeds, United Kingdom); University of Tübingen (Tübingen, Germany); open-access journal; open access paper; scientific journal; Scientific Reports; CT scan; computer tomographic (CT) scan; mummy; 3D printing; 3-D printed; Leeds City Museum; northern England; Ancient Egypt; Egyptian; priest; Nesyamun; scribe; hierarchy; high-ranking; Karnak temple; Thebes, Egypt; reign; Ramses XI; pharaoh of Egypt; biological specimen; shape; supine burial position; groan; coffin; name; spelling; Egyptian hieroglyphs; epigraphy; inscription; popularity; common; translation; translate; God, Amun; Creative Commons Attribution 4.0 International License; ritual; song; death; allergic reaction; disease; suffer; periodontal disease; gum disease; wear; worn; teeth (human); soul; deity; god; wish; flesh; fleshy; vibration; vibrating; timbre; sound recording and reproduction; recorded sound; Homer W Dudley, "Signal transmission," US Patent no. 2,151,091, March 21, 1939.