Computers as Listeners and Speakers
November 4, 2013
It's usually easy to distinguish
male from
female voices, since most women speak and sing at higher
frequencies than most men. If you do a more technical analysis of
speech signals, you see that all speech
information is contained in the
audio frequency band below 20 kHz. Further
experimentation shows that
intelligible speech is contained in frequencies between
300-3400 Hz, with most of the amplitude contained between 80-260
Hz.
The frequency range of intelligible speech was very important in the definition of the
telephone system, since you wouldn't want to spend money on high frequency
components that weren't required. Telephone
research also led to the first form of
digital encoding of speech in a system called the
vocoder, patented in 1939 by
Bell Labs acoustical engineer,
Homer Dudley.[1]
In what was a
tour de force in the era of
vacuum tube electronics, Dudley used a bank of
audio filters to determine the
amplitude of the speech signal in each band. These amplitudes were encoded as digital data for transmission to a remote bank of
oscillators that reconstructed the signal.
The vocoder allowed
compression and
multiplexing of many voice
channels over a single
submarine cable.
Encryption of the digital data allowed secure voice communications, a technique used during
World War II.
The vocoder operated on band-limited signals, independently of their origin. It was over-kill as far as speech signals are concerned, since human speech is contained in definite frequency bands called
formants (see figure). Formants arise from the way that human speech is generated.
Air flow through the
larynx produces an excitation signal that excites
resonances in the
vocal tract.

Spectrograms of the average female (left) and male (right) voicing of vowels. These are the English vowel sounds, 'eh' (bet), 'ee' (see), 'ah' (father), 'oh' (note), and 'oo' as in (boot). Note the overall lower frequencies of the male voice, as well as the slower male cadence. (Fig. 1 of ref. 2, licensed under a Creative Commons License.)[2)]
Knowledge of the way that human speech is created allowed development of a
speech synthesis technique called
formant synthesis, which is
modeled on the physical production of sound in the human vocal tract. This was best developed as
linear predictive coding (LPC), successfully implemented by
Texas Instruments in its
LPC integrated circuits. Texas Instruments used these chips in its
Speak & Spell toy. My
e-book reader has a very good
text-to-speech feature with both male and female speakers.

My favorite talking machine, Robby The Robot, as he appeared at the 2006 San Diego Comic Con.
Robby was a character in the 1956 Movie, Forbidden Planet, which I saw as a nine year old child.
A second favorite would be Bender from Futurama, while my least favorite would be Twiki from Buck Rogers in the 25th Century.
(Photo by Patty Mooney, via Wikimedia Commons.)
It should come as no surprise that research in artificial speech production has led to methods for
speech recognition. The
Wikipedia list of speech recognition software includes quite a few implementations, including the every-popular
Siri,
Google Voice Search, and a number of
free and open-source software (FOSS) packages.
Some early voice recognition software improved
reliability by having a single user speak works from a selected
dictionary to
calibrate the system to his voice. Modern applications try as much as possible to hide the "
computer" part of
computing from the user, so this is no longer done. As an
episode of
The Big Bang Theory shows, such voice recognition has its flaws, even in a one speaker environment. Is speech recognition of multiple speakers in a conversation even possible with today's
technology?
Humans have no trouble with the task of identifying speakers in a group conversation, so how hard would it be for a computer to do the same? A team of
computer scientists in the
Spoken Language Systems Group at MIT's
Computer Science and Artificial Intelligence Laboratory have tackled this problem, which is termed, "
speaker diarization."[3-5] Speaker diarization is the automatic determination how many speakers there are, and which of these speaks when. It would be useful for
indexing and
annotating audio and
video recordings.[4]
A
sonic representation of a single speaker involves the analysis of more than 2,000 different speech sounds, such as the vowel sounds represented in the
spectrogram, above. These can be adequately represented by about sixty
variables.[4] When several speakers are involved in conversation, the diarization problem reduces to a search of a
parameter space of more than 100,000 dimensions. Since you would like to avoid always needing to do diarization on a
supercomputer, you need a way to reduce the complexity of the problem.[4]
As an
analogy of how such a simplification is achieved, consider the cumulative
miles traveled by a
train as a function of
time. If we just consider the
raw data, we would have a
two-dimensional graph of miles (y)
vs time (x), represented by a
straight line. If we execute a
mathematical transformation to
rotate the graph to place the line at the x-axis, then all the variation happens along the x-axis, and we eliminate one of the two dimensions. The MIT research team's approach is to find the "lines" in the parameter space that encode most of the variation.[4]
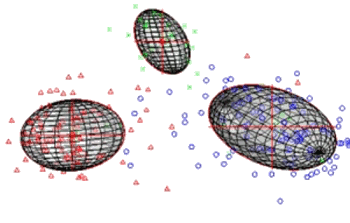
A representation of the cluster analysis of multiple speakers.
(Still image by Stephen Shum from a YouTube Video.[5]
Stephen Shum, a
graduate student of
Electrical Engineering and Computer Science at
MIT, and the lead author of the paper describing the technique, found that a 100-dimension approximation of the parameter space was an adequate representation. In any given conversation, not all speech sounds are used, so a single recording might need just three variables to classify all speakers.[4]
Shum's system starts with an assumption that there are fifteen speakers, and it uses an
iterative process to reduce the number by merging close clusters until the actual number of speakers is reached.[4] The technique was tested with the multi-speaker
CallHome telephone corpus.[3]
References:
- Homer W Dudley, "Signal transmission," US Patent No. 2,151,091, March 21, 1939.
- Daniel E. Re, Jillian J. M. O'Connor, Patrick J. Bennett and David R. Feinberg, "Preferences for Very Low and Very High Voice Pitch in Humans," PLoS ONE, vol. 7, no. 3 (March 5, 2012), Article No. e32719.
- Stephen H. Shum, Najim Dehak, Réda Dehak and James R. Glass, "Unsupervised Methods for Speaker Diarization: An Integrated and Iterative Approach," IEEE Transactions On Audio, Speech, And Language Processing, vol. 21, no. 10 (October 2013), pp. 2015-2028.
- Larry Hardesty, "Automatic speaker tracking in audio recordings," MIT Press Release, October 18, 2013.
- YouTube Video, Clustering method of Speech Recognition, Stephen Shum, October 8, 2013. The algorithm groups the points together that are associated with with a single speaker.
- Web Site of MIT Spoken Language Systems Group.
Permanent Link to this article
Linked Keywords: Male; female; voice; frequency; frequencies; speech; signal; information; audio frequency band; experiment; experimentation; intelligibility; intelligible; voice frequency; hertz; Hz; telephony; telephone system; electronic component; research; digital data; digital encoding; vocoder; Bell Labs; acoustical engineering; acoustical engineer; Homer Dudley; tour de force; vacuum tube; electronics; audio filter; amplitude; oscillator; compression; multiplexing; communications channel; submarine cable; encryption; World War II; formant; air flow; larynx; resonance; vocal tract; spectrogram; English language; cadence; Creative Commons License; speech synthesis; formant synthesis; physical modelling synthesis; linear predictive coding; Texas Instruments; LPC integrated circuit; Speak & Spell toy; e-book reader; speech synthesis; text-to-speech; Robby The Robot; San Diego Comic-Con International; Forbidden Planet; Bender; Futurama; Twiki; Buck Rogers in the 25th Century; Patty Mooney; Wikimedia Commons; speech recognition; Wikipedia list of speech recognition software; Siri; Google Voice Search; ree and open-source software; FOSS; reliability; dictionary; calibration; computer; computing; episode; The Big Bang Theory; technology; computer scientist; Spoken Language Systems Group; Computer Science and Artificial Intelligence Laboratory; MIT; speaker diarization; indexing; annotating; sound recording and reproduction; video recording; acoustic; sonic; spectrogram; variable; parameter space; supercomputer; analogy; mile; train; time; raw data; two-dimensional space; Cartesian coordinate system; graph; straight line; mathematical transformation; rotation; YouTube Video; Stephen Shum; graduate student; Electrical Engineering and Computer Science; iteration; iterative; CallHome telephone corpus.