Word Correlations
July 27, 2012
When you mention "word" to a
computer person, he will think of something far different from what springs into the minds of
"ordinary" people. A computer
word is the group of
bits that can be handled at one time by a
central processor or its
memory. A word can be just a single bit, as in some
bit slice microcontrollers. The first
microprocessor, the
Intel 4004, had a word length of four bits.
The 4004 was followed by the venerable
Intel 8080 and
Zilog Z80, which were eight bit microprocessors. Now it's common for
desktop computers to have 64-bit words, and for
supercomputers to process 128-bit words. For those who need to cut slices of
reality very thin for
simulation and
analysis, 128-bits is equivalent to about three parts in 10
39.

The next Hollywood blockbuster?
This is the cover of a comic book that Zilog produced in 1979 to promote its microprocessors.
The Zilog Z80 quickly took market share from the Intel 8080 for a number of hardware improvements, including operation from a single +5 volt power supply, fewer "glue" chips, and an onboard dynamic memory refresh controller. The Z80 also had an expanded instruction set that included block moves of bytes from one memory location to another.
(Author's copy. (Click for larger image.)
Let's retreat from computerdom and move to the usual definition of a word. The Oxford English Dictionary contains about 600,000 words. It would be difficult memorizing such a large number of words, so
English-speaking people use only about 10,000 of these.
We know quite a few other words, but these usually aren't spoken. They might be
technical, or unusual words found only in reading. Many such
cromulent words[1] can be found in the works of
Shakespeare.
One concordance of Shakespeare's complete works has 28,827 words, although many of these are a
hyphenated combination of other words.
Poets and
novelists are not the only people who have fun with the written word.
Scientists have done some interesting
statistical analyses of
word frequency and other word statistics. I wrote about some of these in two previous articles (
Word Extinction, August 17, 2011 and
Lexical Distance, June 27, 2011).
As can be expected, some words are much more often than others. The word, "the," is the word used most often, and "of" is used about 60% as frequently as "the." The words, "and," "to," and "in" are used about 53%, 46% and 31% as frequently as "the." The following figure shows the relative frequency of the
thousand most common words found in texts on
Project Gutenberg. A source file of data (
CSV format) can be found
here.
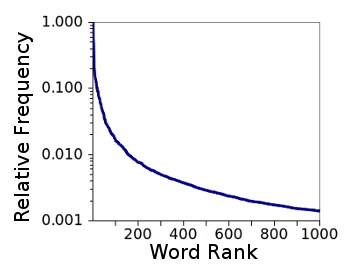
Frequencies of the thousand most common words on the Project Gutenberg web site.
The first 25 words comprise about a third of all texts, and the first hundred words comprise about half of all texts.
(Graphed using Gnumeric)
Another interesting result is that most words in the English languages are eight, or nine, characters long. I would have expected far shorter, since the average word length of the preceding sentence is less than five characters. However, who can argue when the data look so nice, as in the following figure.
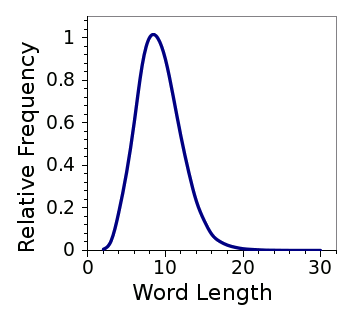
Distribution of English word lengths. Data from Table 7 of ref. 2.[2]
Most words are 8-9 letters long. My blog must be easy to understand, since I seem to use shorter words.
(Graphed using Gnumeric)
A piece of text, of course, will supposedly have a value greater than just that of its aggregate words. Scientists from the
Max Planck Institute for the Physics of Complex Systems (Dresden, Germany) and the
Department of Mathematics of the
Università di Bologna (Bologna, Italy) have just published a paper in the
Proceedings of the National Academy of Sciences in which they look for long-range
correlations of keywords and other text attributes in a variety of English
corpora, including a translation of "
War and Peace."[3-4]
One reason why it's generally easy to make sense of a scientific paper in a foreign language is that the message is contained in
keywords. There are many words that embellish and glue these keywords together, but they are not as important in getting the message across. The Dresden/Bologna team found that keywords appear more frequently in certain passages of text; and that such passages, although distant from each other, use the same words and letters.[4]
Keywords tend to appear in bursts; that is, they will be used repeatedly is a certain section of text, and they will be nearly absent in the rest of the text. Frequently used words are more representative of the context of a section of text. Going to an especially
abstract level, the Dresden/Bologna team encoded text as a
binary string in which
vowels were designated by a one, and
consonants were designated by a zero.[3] In that case, the
mathematical tools to determine correlation are simplified.[4]
The authors state that their approach could be useful for
Internet search, and to identify
plagiarism.[4]
References:
- The derived meaning of the word, cromulent, is fine, valid, or acceptable. In a search for a possible etymology of cromulent, I found nothing reasonable. The closest Latin word is crumena/crumina, or "purse." The closest Greek words are krommyon (κρομμυον, "onion") and chroma (χρωμα, "surface of a body; skin; complexion).
- Reginald D. Smith, "Distinct word length frequencies: distributions and symbol entropies," arXiv Preprint Server, July 15, 2012; appears, also, in Glottometrics, vol. 23 (2012), pp. 8-23.
- Eduardo G. Altmann, Giampaolo Cristadoro and Mirko Degli Esposti, "On the origin of long-range correlations in texts," Proc. Natl. Acad. Sci., vol. 109, no. 29 (July 17, 2012), pp. 11582-11587.
- In search of the key word - Bursts of certain words within a text are what make them keywords, Max Planck Institute for the Physics of Complex Systems Press Release, July 17, 2012
Permanent Link to this article
Linked Keywords: Computer scientist; Peter Griffin; ordinary" people; computer architecture; word; bit; central processing unit; central processor; computer memory; bit slice; microprocessor; Intel 4004; Intel 8080; Zilog Z80; desktop computer; supercomputer; reality; simulation; analysis; Captain Zilog; Hollywood blockbuster; comic book; glue logic; "glue" chip; dynamic memory refresh controller; Oxford English Dictionary; English language; English-speaking; technology; technical; cromulent; Shakespeare; concordance of Shakespeare's complete works; hyphen; hyphenated; poet; novelist; scientist; statistical analysis; word frequency; thousand most common words; Project Gutenberg; comma-separated values; CSV format; Gnumeric; Max Planck Institute for the Physics of Complex Systems (Dresden, Germany); Department of Mathematics; Università di Bologna (Bologna, Italy); Proceedings of the National Academy of Sciences; correlation; text corpus; corpora; War and Peace; keyword; principle of abstraction; abstract level; binary code; string; vowel; consonant; mathematics; Internet search; plagiarism; etymology; Latin; Greek; arXiv.