Word Extinction
August 17, 2011
The
Oxford English Dictionary, lovingly referred to as just OED, contains about 600,000 words.
English-speaking people use only a small fraction of these, since it's quite impossible to memorize such a large number of words.
Basic English is just
850 words. An extended list of basic English words for Wikipedia articles contains just
1500 words.
The
Voice of America has its own version of
Special English that's based on a
VOA Special English Word Book of 1510 words. The "active" vocabulary of an individual, independent of his language, is
estimated to be about 10,000 words.
People generally know many more words that these 10,000, but they aren't often spoken. They may be encountered only in reading. If you count the number of distinct words in the entire
Shakespearean corpus, there are about 20,000-25,000. An exact enumeration isn't possible, since it hinges on how you define a
distinct word.
One concordance of Shakespeare's complete works has 28,827 words, although many of these are a hyphenated combination of other words. I probably know about 30,000 words, but many thousands of these are
scientific words that are not useful in
seduction.
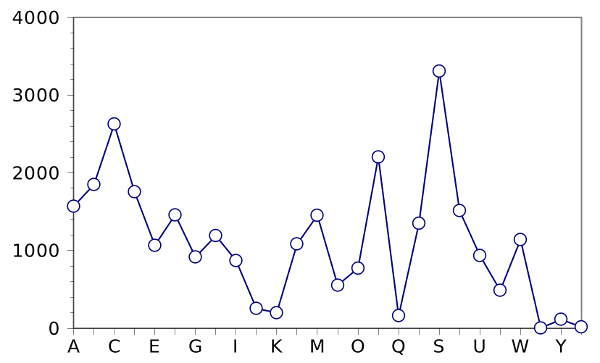
Frequency of words by first letter in the complete works of William Shakespeare. (Graphing via Gnumeric, from data found at Open Source Shakespeare)
Just as when we delete old
computer files to make room for others, people tend to do the same for vocabulary words. Adding a word means deleting another, so words tend to become extinct. The concept of word
extinction is analyzed in a recent paper published on the
arXiv Preprint Server.[1]
This study makes use of the database of the
Ngram Viewer from
Google that I reviewed in a
previous article (Culturomics, January 13, 2011). [2-6] The Google database is somewhat like a
concordance of every written word of all books scanned by Google. These lists are available for free download, and they are
copyright-free. The project has its own web site at
Culturomics.org. Here's a breakdown of the total numbers of non-distinct words scanned for the following languages.[3]
• English - 361 billion
• French - 45 billion
• Spanish - 45 billion
• Russian - 35 billion
• Chinese - 13 billion
• Hebrew - 2 billion
The study used Google word data for English, Spanish, and Hebrew texts for the period 1800-2008. The combined corpus had 10
7 distinct words. That's ten million for three languages, or about 3.3 million words per language.
Since the OED has just 0.6 million words, why the five-fold discrepancy? Google's count must include a huge number of misspelled words as distinct words. Most of these likely derive from errors in the
optical character recognition process. Also, it appears that every
number (e.g., 1234) is listed as a distinct word, including
currency values ($12.34). Fortunately, none of the errors or inclusion of the numbers affect the paper's analysis or conclusions.
One example of the extinction process involves
regular and
irregular verb forms. Irregular forms will often become regularized over time, and previous work shows that irregular verbs which are often used are less likely to become regularized. The
half-life of an irregular verb was found to scale with the
frequency of its usage. An irregular verb that is used a hundred times less frequently regularizes ten times faster. Quantitatively, irregular verb death scales as (
1/√r), where r is the verb's relative use.[7]
This
equilibrium between word birth and death has many recent examples. Early in my career, I would often use the words,
memo and
memorandum. I rarely use those words, now, but I regularly use
blog and
email, which are words I never used twenty years ago. Often, shorter words will trump longer words over time; and scientific words will converge on their English form. Both of these ideas are demonstrated in the figure, below, that shows how the term,
Roentgenogram, has been displaced by the simpler,
Xray.
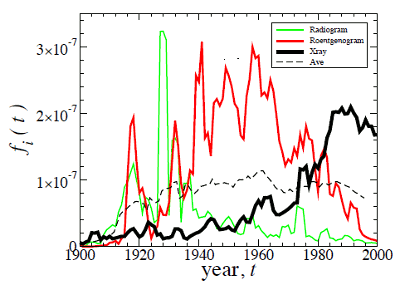
"X" marks the spot.
The term, Xray, snuffing Roentgenogram to extinction.
(Fig. 1 of Ref. 1, via arXiv Preprint Server))
As the authors of the study write,
"Our results support the intriguing concept that a language's lexicon is a generic arena for competition which evolves according to selection laws that are related to social, technological, and political trends... just as firms compete for market share leading to business opportunities, and animals compete for food and shelter leading to reproduction opportunities, words are competing for use among the books that constitute a corpus."
References:
- Alexander M. Petersen, Joel Tenenbaum, Shlomo Havlin and H. Eugene Stanley, "Statistical Laws Governing Fluctuations in Word Use from Word Birth to Word Death," arXiv Preprint Server, July 19, 2011
- Jean-Baptiste Michel, Yuan Kui Shen, Aviva Presser Aiden, Adrian Veres, Matthew K. Gray, The Google Books Team, Joseph P. Pickett, Dale Hoiberg, Dan Clancy, Peter Norvig, Jon Orwant, Steven Pinker, Martin A. Nowak, and Erez Lieberman Aiden, "Quantitative Analysis of Culture Using Millions of Digitized Books," Science, vol. 331, no. 6014 (January 14, 2011), pp. 176-182.
- Dan Charles, "All Things Considered - Google Book Tool Tracks Cultural Change With Words," National Public Radio, December 16, 2010.
- Steve Bradt, "Oh, the humanity - Harvard, Google researchers use digitized books as a 'cultural genome'," Harvard University News Release, December 16, 2010.
- Patricia Cohen, "In 500 Billion Words, New Window on Culture," The New York Times, December 16, 2010.
- Erez Lieberman, Jean-Baptiste Michel, Joe Jackson, Tina Tang, and Martin Nowak, "Quantifying the Evolutionary Dynamics of Language," Nature, vol. 449, no. 7163 (11 October 2007), pp. 713-716; also available at the Nature web site.
- Erez Lieberman, Jean-Baptiste Michel, Joe Jackson, Tina Tang and Martin A. Nowak, "Quantifying the evolutionary dynamics of language," Nature, vol. 449, no. 7163 (October 11, 2007), pp. 713-716.
Permanent Link to this article
Linked Keywords: Oxford English Dictionary; English language; Basic English; Basic English alphabetical wordlist; Extended Basic English alphabetical wordlist; Voice of America Special English VOA Special English Word Book; vocabulary development; Shakespearean; corpus; concordance of Shakespeare's complete works; scientific; seduction; William Shakespeare; Gnumeric; Open Source Shakespeare; computer file; extinction; arXiv Preprint Server; Ngram Viewer; Google; Culturomics; concordance; copyright; Culturomics.org; English; French; Spanish; Russian; Chinese; Hebrew; optical character recognition; number; currency; regular verb; irregular verb; half-life; frequency; equilibrium; Alexander M. Petersen; Joel Tenenbaum; Shlomo Havlin; H. Eugene Stanley.