Alberti's Conjecture
November 30, 2012
I've written about the
frequency of occurrence of
alphabet characters in a
previous article (What's in a Name? April 11, 2011). Some letters are
more common in words than others, and there are
Internet sources of
frequency tables of letter occurrence for many
languages.[1] Differences in letter frequency exist, depending on the particular text
corpus analyzed, and these are useful in determining the authorship of
anonymous works, such as the
Federalist Papers.
The letter
e is the most common letter of the
English language (12.7%), followed by
t (9.056%),
a (8.167%) and
o (7.507%). The twelve most frequent letters (e,t,a,o,i,n,s,h,r,d,l,c), or less than half the 26 letter English alphabet, are used about 80% of the time. It's almost as if we can throw half our alphabet away, and still be understood.[2]
Before the advent of powerful
cryptographic methods, such as the
Advanced Encryption Standard (AES),
cryptologists, would use
letter frequency analysis to
decipher codes. Presently, it's often easier to decode messages using alternative techniques (see figure).
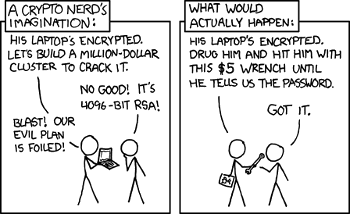
The always entertaining xkcd comic.
Click on the image to see what "Crypto-Nerd" translates to "Cryptomaniac" in Russian.
(xkcd comic no. 538).
Letter frequency analysis has a long history, as recalled in a recent arXiv article by
Bernard Ycart of the
Laboratoire Jean Kuntzmann,
Université Joseph Fourier,
Grenoble, France.[3] The most famous historical reference to letter frequency analysis is an 1851 letter by
mathematician,
Augustus de Morgan, that suggests the use of letter frequency counts to determine
authorship.[3]
Ycart's paper is focused on a particular letter frequency conjecture, four
centuries before de Mogan's letter, by
Leon Battista Alberti (1404-1472), a
Renaissance
polymath. Alberti stated that
Roman poets used slightly more
vowels than their
orator contemporaries.

Renaissance polymath, Leon Battista Alberti (1404-1472).
Alberti, an artist, author and poet, dabbled in a variety of subjects, including architecture, linguistics, philosophy and cryptography.
(Via Wikimedia Commons))
Alberti's "De componendis cifris"[4] (c. 1466), the first
western text on cryptology, contains the following passage in section IV:
From my calculations, it turns out that in the case of poetry, the number of consonants exceeds the number of vowels by no more than an octave, while in the case of prose the consonants do not usually exceed the vowels by a ratio greater than a sesquialtera. If in fact we add up all the vowels on a page, let's say there are three hundred, the overall sum of the consonants will be four hundred.[5-6]
In
translations like this, it's also necessary to translate the
mathematical notation to make it understandable to modern readers. For poets, the vowel equation would be
(1 − V ) − V ≤ 1/8; that is,
V > 7/16. For orators, it's
(1 − V)/V ≤ 4/3, or
V > 3/7. In short, Alberti claims is that the text of Roman poets contains about 43.75% vowels, and the text of Roman orators contains about 42.86% vowels; or, about a
percent less.[3] Alberti would have included "Y" as one of the vowels.
Alberti doesn't name his source material, but Ycart assembled a group of texts that Alberti may have analyzed. In the days before
computers, such analysis must have been tedious, so I speculate that Alberti had hired help. I, however, have a computer, so I wrote a simple analysis program (
source code,
here).
As my source material, I chose a long oration by
Cicero,[7] Book 1 of
Vergil's Aeneid,[8] and the first book of
Odes by
Horace.[9] Cicero surely qualifies as an orator, and Horace as a poet. Vergil, too, is a poet, but the Aeneid is a
narrative, and this appears to place him in the oration category, as shown in the table.
| | Cicero | Vergil | Horace |
| Vowels(%) | 45.09 | 44.90 | 46.26 |
| Vowels(%, Y included) | 45.10 | 45.18 | 46.63 |
My evidence is merely
anecdotal, but Ycart does a thorough analysis in his paper (twenty Latin texts containing five million letters). His evidence supports Alberti's conjecture.
It's also interesting that English texts have a far fewer percentage of vowels than Latin. The vowel content of English is just 38.1% when "Y" is excluded, and 40.1% when "Y" is included. My book,
Mother Wode, has 38.39% vowels when "Y" is excluded, and 40.17% when "Y" is included.
References:
- Letter Frequency page on Wikipedia.
- Devlin M. Gualtieri, "FauxCrypt - A Method of Text Obfuscation," arXiv Preprint Server, April 28, 2010.
- Bernard Ycart, "Alberti's letter counts," arXiv Preprint Server, October 26, 2012.
- L. B. Alberti, "De componendis cyfris," (Latin text, 1466), PDF file.
- "Sic enim adnotasse videor apud poetas vocales a consonantibus numero superari non amplius quam ex octava; apud rhetores vero non excedere consonantes ferme ex proportione quam sesquitertiam nuncupant. Nam si fuerint quidem connumeratae in unumque collectae omnes istius generis paginae vocales numero puta tricentarum, reliquarum omnium consonantium numerus una coadiunctus erit fere quadringentarum."
- L. B. Alberti, De componendis cifris, transl. K. Williams, in K. Williams, L. March and S.R. Wassel, Eds., "The mathematical works of Leon Battista Alberti," Birkäuser Springer (Basel, 2010), pp. 171-200 (as cited in ref. 3).
- M. Tvllivs Cicero, "Post Reditvm in Senatv Oratio," The Latin Library.
- P. Vergilivs, "Maronis Aeneidos, Liber Primvs," The Latin Library.
- Q. Horativs Flaccus, "Carminvm, Liber Primvs," The Latin Library.
Permanent Link to this article
Linked Keywords: Frequency; alphabet; letter frequency; Internet; frequency table; language; corpus; anonymity; Federalist Papers; English language; cryptography; Advanced Encryption Standard; cryptologist; letter frequency analysis; cryptanalysis; decipher; code; xkcd comic no. 538; arXiv; Bernard Ycart; Laboratoire Jean Kuntzmann; Université Joseph Fourier; Grenoble, France; mathematician; Augustus de Morgan; authorship; century; Leon Battista Alberti; Renaissance; polymath; Latin literature; Roman poet; vowel; orator; Wikimedia Commons; western civilization; translation; mathematical notation; percentage; percent; computer; source code; Cicero; Vergil; Aeneid; Odes; Horace; narrative; anecdote; Mother Wode.